Bigtable论文阅读
本文是我对Bigtable论文进行第一轮阅读所做的笔记。对于理解欠妥的地方,欢迎发送邮件至tinylcy (at) gmail.com讨论。
Data Model
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted arrays of bytes.
Bigtable是稀疏的、分布式的、持久化的、多维度的、顺序的map,我们可以将Bigtable的数据模型抽象为一系列的键值对,满足的映射关系为:(row:string, column:string, time:int64) -> string。
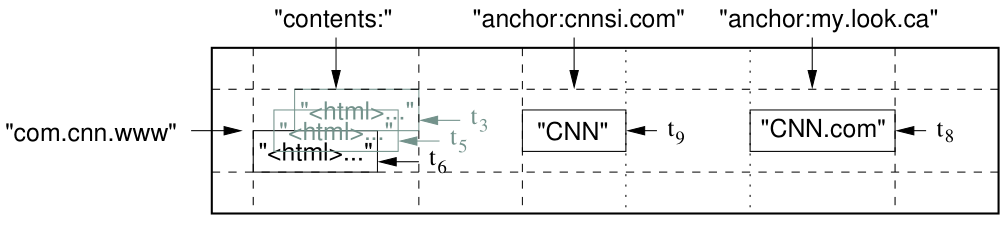
A slice of an example table that stores Web pages. The row name is a reversed URL. The contents column family contains the page contents, and the anchor column family contains the text of any anchors that reference the page. CNN’s home page is referenced by both the Sports Illustrated and the MY-look home pages, so the row contains columns named anchor:cnnsi.com and anchor:my.look.ca. Each anchor cell has one version; the contents column has three versions, at timestamps t3 , t5 , and t6.
Rows
- The row keys in a table are arbitrary strings.
- Bigtable maintains data in lexicographic order by row key.
- The row range for a table is dynamically partitioned. Each row range is called a tablet, which is the unit of distribution and load balancing.
- Bigtable内部的行键(row key)会按照字典序排序,因为系统庞大且为分布式,所以排序这个特性会带来很大的好处,行的空间邻近性可以确保当我们在扫描表时,我们感兴趣的记录会大概率的汇聚到一起。
- Tablet是Bigtable分配和负载均衡的单元,Bigtable的表根据行键自动划分为tablet。最初表都只有一个tablet,但随着表的不断增大,原始的tablet自动分割为多个tablet。
Column Families
- Column keys are grouped into sets called column families, which form the basic unit of access control.
- All data stored in a column family is usually of the same type.
- A column family must be created before data can be stored under any column key in that family; after a family has been created, any column key within the family can be used.
- Column families rarely change during operation. In contrast, a table may have an unbounded number of columns.
- Bigtable把所有的列划分为若干个列族(column family),每个列族一般存储相同类型的数据。关于这点,我联想到在大部分的NoSQL数据库中,始终贯穿的一个理念就是面向聚合,NoSQL往往是应用在集群环境中,而在集群环境下的跨表JOIN实现起来会比单机关系型数据库复杂的多,所以在设计表时,我们就把相同类型的数据尽可能汇聚在一起,即每个列族一般存储相同类型的数据。
- 一行的列族很少变化(改变的开也会比较大),但是列族里的列是允许随意增减的。列键(column key)是通过family:qualifier来定位的。
Timestamps
- Each cell in a Bigtable can contain multiple versions of the same data; these versions are indexed by timestamp.
- Different versions of a cell are stored in decreasing timestamp order, so that the most recent version can be read first.
- 对于具有相同行键(row key)和列键(column key)的数据(cell),Bigtable会存储这个数据的多个版本,这些版本通过时间戳来区分,用户可以版本的数量。
- 数据按照时间戳降序排序,这样可以保证取到的数据是最新的。同时,过期的数据也会被回收。
我们现在再回顾论文一开始便提到的:A Bigtable is a … map,传统的map由一系列键值对组成,在Bigtable中,对应的键是由多个数据复合而成的,即row key,column key和timestamp。
Building Blocks
Bigtable的实现依托于Google的几个基础组件:Google File System,Google SSTable 和 Chubby。
- Bigtable uses the distributed Google File System(GFS) to store log and data files.
- The Google SSTable file format is used internally to store Bigtable data. An SSTable provides a persistent, ordered immutable map from keys to values.
- Bigtable relies on a highly-available and persistent distributed lock service called Chubby. Bigtable uses Chubby for a variety of tasks.
- to ensure that there is at most one active master at any time;
- to store bootstrap location of Bigtable data;
- to discover tablet servers and finalize tablet server deaths;
- to store access control lists;
Chubby是一个高可靠用于分布式的锁服务,其目的是解决分布式一致性的问题,通过Paxos算法实现。
Implementation
Bigtable的系统结构由三个部分组成,包括客户端中用于通信的Library、一个主节点(master server)和一系列从节点(tablet servers)。整个架构可以从下图清晰的体现出来。
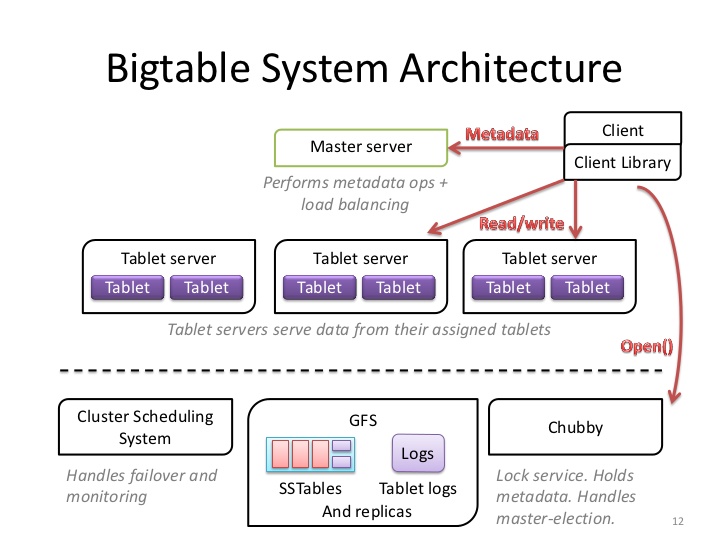
- The master is responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, and garbage collection of files in GFS.
- Each tablet server manages a set of tablets and handles read and write requests to the tablets that it has load, and also splits tablets that have grown too large.
需要注意的是,客户端在读写数据时直接和tablet server通信,不需要经过master server,而且在Bigtable中,客户端获取tablet位置信息也不依赖于master server。因此在大多数情况下,客户端都不会和master server通信,这就大大降低了由单个master server造成的单点故障的可能性。关于这点我们从上图也可以得知。
Tablet Location
前面已经提到,客户端在获取tablet位置信息时并不需要经过master server,那么tablet的位置信息时如何定位的?首先,需要了解tablet的位置信息是如何存储的。Bigtable通过类似B+树的结构来存储tablet的位置信息,如下图所示。
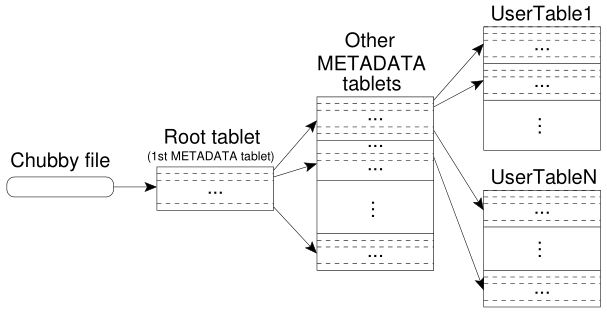
- The first level is a file stored in Chubby that contains the location of the root tablet. The root tablet contains the location of all tablets in a special METADATA table.
- Each METADATA tablet contains the location of a set of user tables.
Root tablet存储了一系列METADATA tablet的位置信息,而user tablet的位置信息存储在这些METADATA tablets中。论文中提到root tablet是不允许被分片的,这么做的目的是保证整个tablet location hierarchy不超过3层。这意味着Bigtable的数据存储还是有上限的,于是论文计算了3层架构能够存储的tablet的数量。
Each METADATA row stores approximately 1KB of data in memory. With a modest limit of 128 MB METADATA tablets, our three-level location scheme is sufficient to address 2^34 tablets (or 2^61 bytes in 128 MB tablets).
客户端会缓存tablet的位置信息,客户端在获取tablet的位置信息时,会涉及到两种情况。
- 如果客户端没有缓存目标tablet的位置信息,那么就会沿着root tablet定位到最终的tablet,整个过程需要3个network round-trips。
- 如果客户端缓存了目标tablet的位置信息,但是到了目标tablet后发现原来缓存的tablet位置信息过时了,那么会重新从root tablet开始定位tablet,整个过程需要6个network round-trips。
Tablet Assignment
当tablet server启动时,它会在Chubby的某个特定目录下创建并获取一个锁文件(互斥锁),这个锁文件的名称是唯一表示该tablet server的。master server通过监控这个目录获取当前存活着的tablet server的信息。
- 如果tablet server失去了锁(比如网络问题),那么tablet server也就不再为对应的tablet服务了。
- 如果锁文件存在,那么tablet server会主动获取锁。
- 如果所文件不存在了,那么tablet server就永远不会再服务对应的tablet了,所以tablet server就会自己kill掉自己。
- 当tablet server要终止时,它会自己释放占有的锁,master server就会把该tablet server上的tablet分配给其它的tablet server。
那么maser server是如何获知tablet server不再服务了呢?master server会定期轮询每个tablet server的锁状态。如果tablet server报告自己失去了已经失去了锁,或者master server不能获取tablet server的状态,那么master server就会尝试去获取tablet server对应的锁文件。如果master server获取到了所文件,并且Chubby是处于正常工作的状态的,此时master server就确认tablet server已经无法再提供服务了,master server删除相应的锁文件并把tablet server对应的tablet分配给新的tablet server。
如果master server与Chubby之间出现了网络问题,那么master server会自己kill掉自己。但是这并不会影响tablet与tablet server之间的分配关系。
master server的启动需要经历一下几个阶段。
- master server需要从Chubby获取锁,这样可以确保在同一时刻只有一个master server在工作。
- master server扫描Chubby下特定的目录(即tablet server创建锁文件的目录),获取存活着的tablet server的信息。
- master server与存活着的tablet server通信,获取已被分配到tablet server的tablet信息。
- master server扫描METADATA tablet,获取所有的tablet信息,然后把未分配的tablet分配给tablet server。
在论文Section 5.2中有一段话还有待理解,如下。
One complication is that the scan of the METADATA table cannot happen until the METADATA tablets have been assigned. Therefore, before starting this scan (step 4), the master adds the roottablet to the set of unassigned tablets if an assignment for the root tablet was not discovered during step 3. This addition ensures that the root tablet will be assigned. Because the root tablet contains the names of all METADATA tablets, the master knows about all of them after it has scanned the root tablet.
当出现如下几种情况时,tablet的分配情况会发生变化。
- tablet的创建和删除。
- 已有的两个tablet合并为一个较大的tablet。
- 已有的一个tablet分割为两个较小的tablet。
对于前两种情况,master server可以马上调整(因为它们是发生在master server上的),但是对于tablet分割,由于它是发生在tablet server上的,因此需要tablet server通知master server。论文关于这一点的描述如下。
The tablet server commits the split by recording information for the new tablet in the METADATA table. When the split has committed, it notifies the master.
Tablet Serving
tablet的持久化是通过存储为GFS文件的形式实现的,下图描述了tablet更新操作的实现。
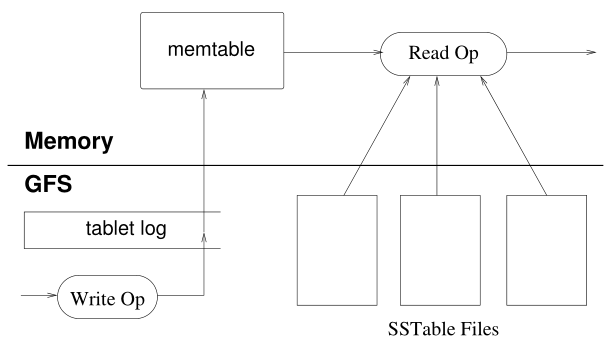
当发生更新时,首先将更新操作写到tablet log日志文件中去,然后把待更新的内容先写到memtable中,memtable是内存中一个排序的缓冲,保存了最近的一次更新操作的内容。更早的更新内容会被持久化到SSTable文件中。