MapReduce论文阅读
大四时曾经粗略的阅读过这篇论文,并且已经写过不少的MapReduce程序,所以介绍性的内容不再赘述。再次阅读这篇论文的原因是为了更系统的学习分布式的相关知识,我开始跟进MIT 6.824: Distributed Systems,而完成这门课程的第一个lab的前提便是阅读这篇论文。
这篇笔记重点分析了MapReduce的执行流程以及容错机制,因为是个人理解,若有分析不妥之处欢迎发送邮件至tinylcy (at) gmail.com讨论交流。
Execution Overview
根据不同的环境,MapReduce的实现方式有多种,比如基于共享内存、基于NUMA多处理器环境等等。而Google内部实现的MapReduce基于如下环境。
- 双核
x86处理器,Linux操作系统,每台机器有2~4GB的内存。 - 使用商用的网络设备,例如
100M/1G带宽网卡。 - 集群是由成百上千台上述配置的设备组成的,因此集群中节点出现故障应该视为常态。
- 存储设备采用的是廉价的
IDE硬盘。在这种不可靠的硬件上,Google实现了一个分布式文件系统GFS,通过备份和冗余来保证可靠性和可用性。 - 用户将作业(
job)提交到调度系统,每个作业由多个任务(task)组成,调度系统负责将任务分配到集群空闲的节点上。
在Map阶段,输入数据会被自动划分为M个分片,这些分片可以在不同的节点上被并行处理。在Reduce阶段,根据一定的划分规则(例如hash(key) mod R),中间数据会被划分为R个分片,这R个分片也可以被多个节点同时处理。Reduce阶段的分片个数R和分片规则可以由用户指定。MapReduce的执行流程如下图所示。
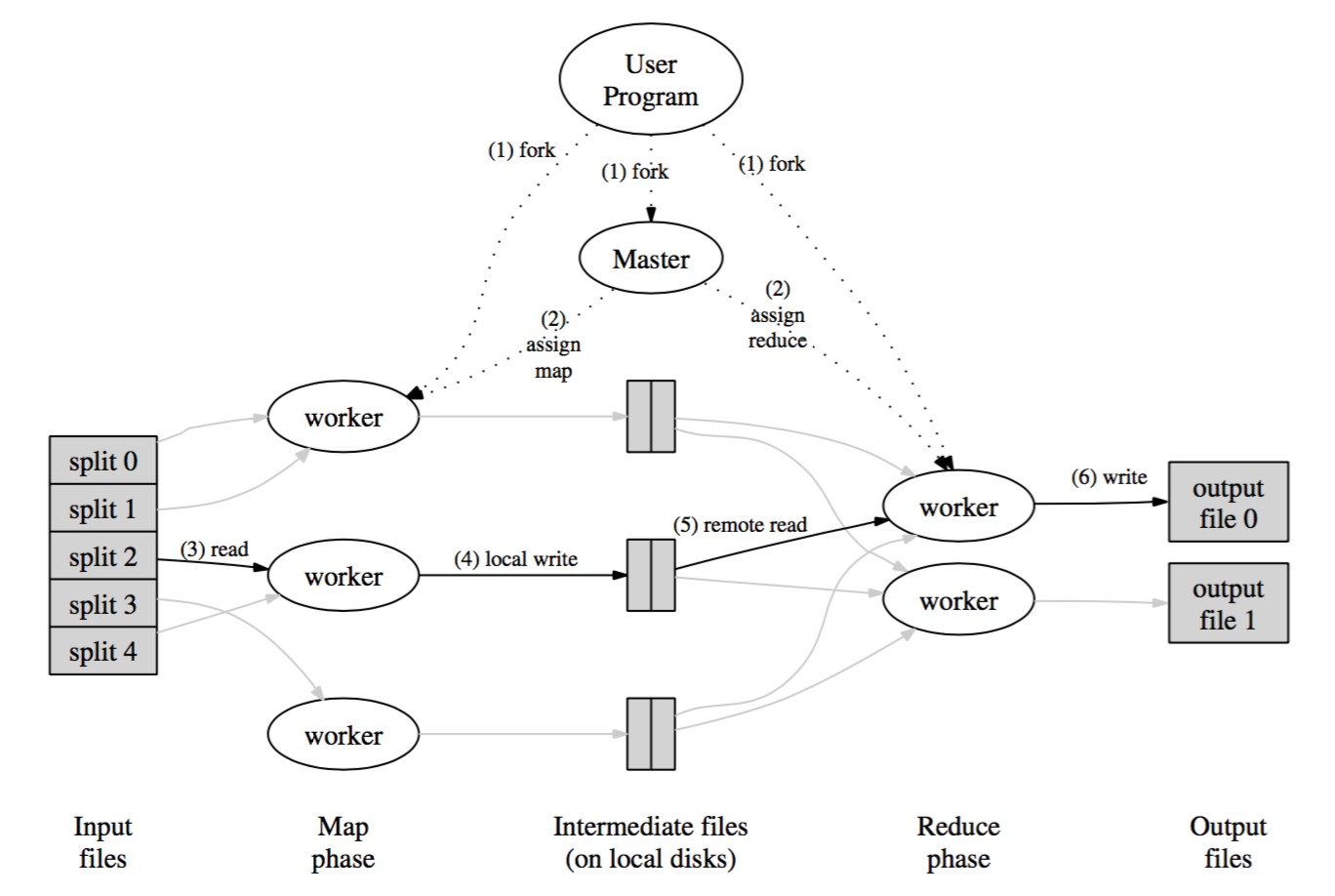
整个执行流程可以划分为如下几个阶段,上图中的数字也标识了这几个阶段。
- 用户程序将输入数据切分为
M个分片(分片的大小一般为16~64MB,用户可以设置分片大小),并把用户程序拷贝到集群中的多个节点。因为数据要比程序大得多,所以“拷贝程序”要比“拷贝数据”高效的多。 - 在拷贝程序到节点的过程中,有一个节点比较特殊:
master节点。其余的节点都为worker节点,worker节点负责执行具体的任务,这些任务通过master节点来分配。任务又分为map task和reduce task。 - 被分配到
map task的worker(map worker)会读取相应的输入分片,并将输入分片中的数据解析为一系列的key/value pairs,然后将这些key/value pairs输入到用户定义的map function,map function输出的key/value pairs会被缓存到内存中,而不是直接写入磁盘。 - 由
map function输出的,缓存在内存中的key/value pairs会被划分为R个分区,并定期写入到本地磁盘中。写入磁盘的位置会被推送给master节点,master节点会将磁盘的位置信息转发给下一阶段执行reduce任务的节点(reduce worker)。 reduce worker在接收到磁盘的位置信息后开始读取相应的磁盘中的数据,当所有的数据读取完毕后,reduce worker会在内存中按照key将所有的key/value pairs进行一次排序。论文认为这次排序是必要的原因是不同的key往往会映射到同一个reduce worker。reducer worker遍历已排好序的key/value pairs,每遇到一个不同的key,便将该key和对应的一系列value传递给用户定义的reduce function,这个过程同时解释了为什么在上一阶段reduce worker要对数据进行排序(论文Section 4.2提到了按照key排序的两个优势,一是支持高效随机按key的查找,二是已经排好序的数据可以方便用户的操作)。reduce function将输出数据append到最终的输出文件中。- 当所有的
map task和reduce task都完成了,master唤醒用户程序并返回。
在执行完整个流程后,会有R个输出文件,每个reduce worker对应一个。这R个输出文件一般不需要合并,因为它们往往是下一个MapReduce处理逻辑的输入数据。
Master Data Structures
master会记录每个map task和reduce task的状态,包括idle、in-progress和completed。同时,master还会记录non-idle task对应的worker的信息。- 对于每个
map task,master会记录下map function输出的R个分片的位置信息和大小。这些信息会被推送到处于in-progress状态的reduce worker上。
Fault Tolerance
由于运行在规模庞大并且廉价的硬件上,因此容错性变得非常重要。
Worker Failure
master会定期ping worker,如果worker没有响应并且超过了一定的次数,那么master就认为worker已经failed了。因此,所有在该worker上完成的task的状态将会被重置为初始的idle状态,并且这些task需要被重新分配到其它的worker上去。类似的,该worker上处于in-progress状态的task也会被重置为最初的idle状态,并被重新分配到其它worker上去。
对于已完成的map task,也需要重新被执行。因为map task的输出是在worker的本地磁盘上,因为worker已经失联了,所以map task的输出数据自然也获取不到。对于已完成的reduce task,不再需要重新执行。因为reduce task的输出是在全局的文件系统(GFS)上。
如果一个map task一开始运行在worker A上,接着由于worker A failed导致该map task迁移到worker B上。那么读取该map task输出数据并且处于正在执行的reduce worker会收到重新执行reduce task的通知,任何还未开始读取数据的reduce task也会收到通知。reduce worker接下来会从worker B上读取数据。
Master Failure
可以通过定期建立检查点的方式来保存master的状态。但是,Google当时的做法是考虑到只有一个master,所以master出现故障的概率很小,如果出现故障了,重新开始整个MapReduce计算。
Locality
网络带宽在计算环境中属于一种非常稀缺的资源,利用输入数据的特性可以减小网络带宽。
- 输入数据由
GFS来管理,GFS把数据存储在集群节点的本地磁盘上,GFS将文件分割为64MB大小的块,并且针对每个块会做冗余(一般冗余2份)。master利用输入数据的位置信息,将map task分配给输入数据所在的节点。 - 如果在计算过程中出现了失败的情况,那么
master会把任务调度给离输入数据较近的节点。
Task Granularity
从上文我们可以得知,map阶段被划分成M个task,reduce阶段被划分成R个task,M和R一般会比集群中节点的个数大得多。每个节点运行多个task有利于动态的负载均衡,加速worker从失败中恢复。
在具体的实现中,M和R的大小是有实际限制的,因为master至少要做O(M+R)次的调度决策,并且需要保持O(M*R)个状态。
通常情况下,R的大小是由用户指定的,而对M的选择要保证每个task的输入数据大小,即一个输入分片在16MB~64MB之间,这样可以最大化的利用数据本地性。
Backup Tasks
导致整个MapReduce计算过程被延迟的原因之一是过多的时间花费在最后几个map task或reduce task上。导致这个问题的原因由很多,可能是因为task所在的节点硬盘的读写速度非常慢,同时master又有可能把新的task分配给了该节点,所以引入了更加激烈的CPU竞争、内存竞争。
一种通用的解决方案是在整个MapReduce计算快要结束时,master对当前处于in-progress状态的task进行备份,无论是原来的task执行完毕还是备份的task执行完毕,那么就认为该task完成了。