我对Raft的理解 - Two
我们已对 Raft Leader 选举进行了理解,Leader 一旦被选举出来,对外提供服务,对内协调日志复制。日志复制是 Raft 共识算法最核心的部分,我们逐步递进的去理解 Raft 是如何通过添加限制条件来保证日志能够被正确的复制。
Slide 11
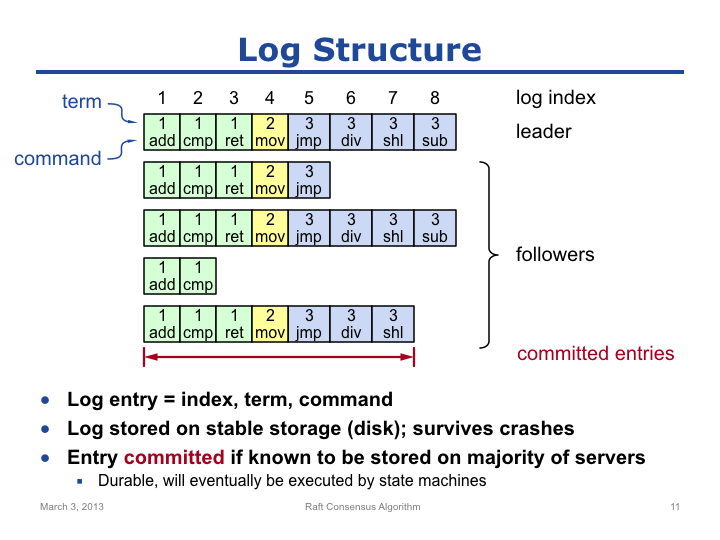
每个节点都维护了一份私有的日志的拷贝,节点存在宕机的风险,为了保证宕机后能够恢复日志,日志需要持久化存储在类似磁盘等介质中。日志由一组日志项组成,每个日志项(Log Entry)包含三部分:Index、Term 和 Command。Index 指示了日志项在日志中的索引,它是日志项的附加属性,类似数组元素下标;Term 指示了日志项被创建时 Leader 所处的任期;Command 指示了日志项包含的操作。
Slide 11 中有 1 个 Leader,4 个 Follower,Leader 需要将日志项正确的复制到 Follower。注意,Leader 的目标并不在于将所有的日志项都复制到 Follower,而在于复制已经 Committed 的日志项。Committed 是 Raft 中另一个非常重要的概念,需要好好理解。那么什么样的日志可以被认为是 Committed 的?我们先给出一个定义:如果某个日志项已经被复制到了大多数节点,那么就可以认为该日志项是 Committed 了,Raft 需要保证,已经 Committed 的日志项会永远存在于大部分节点的日志中。不过,目前这个定义并不能保证日志被正确的复制,还需要添加限制条件。
按照目前对 Committed 的定义,日志项 1 至日志项 7 已经被 Leader 复制到了大部分节点,因此可以认为前 7 项日志项已经 Committed 了。Committed 的日志项可以被状态机执行,而只有被状态机执行,才能响应客户端。
Slide 12

Raft 反复强调算法的可理解性,在日志复制的过程中,Raft 将问题再次分解:Leader 正常运行时的日志复制和 Leader 变更后的日志复制。Leader 正常运行时的日志复制比较简单,分为以下 5 个步骤。
- 客户端向 Leader 发送指令,如果客户端向 Follower 发送了指令,Follower 会将请求重定向至 Leader。
- Leader 创建日志项并 Append 至日志中。
- Leader 向 Follower 发送 AppendEntries 消息,消息中包含了任期 Term 和指令(消息内容会在下文扩展)。
- Follower 收到 AppendEntries 消息后,也会将日志 Append 至自己的日志中,然后响应 Leader。
- 如果 Leader 收到了大多数 Follower 的响应,说明日志项已经被复制到大多数节点了,即日志项已 Committed,Leader 将指令传递给状态机执行,并将结果返回给客户端。然后,Leader 向 Follower 发送 AppendEntries 消息,通知 Follower 该日志项已经 Committed,Follower 在收到消息后也会将指令传递给状态机执行。
如果 Follower 宕机,或者响应特别慢怎么办?Raft 会不断重试 RPC 请求直到成功。但是这对 Raft 的性能并不会有影响,因为 Leader 只需要收到大多数 Follower 的响应即可。
Slide 13

Raft 解决的核心问题是如何安全的复制日志,使大多数节点都拥有已经 Committed 的日志。如果日志能够达成一致,那么 Raft 可以做出以下承诺。
- 位于不同节点的两个日志项如果有相同的 Index 和 Term,那么他们有相同的指令。
- 位于不同节点的两个日志项如果有相同的 Index 和 Term,那么该日志项之前的所有日志项也是相同的,包括 Index、Term 和指令。
基于以上两个承诺,可以进一步得出:如果某个日志项已经是 Committed,那么该日志项之前的所有日志项也已是 Committed 的。可以这么理解:如果某个日志项是 Committed 的,那么说明该日志项已经被复制到了大多数节点,根据两个承诺,该日志项之前的所有日志项是也都已经被复制到了大多数节点,因此也是 Committed 的。
注意,不要忘记目前我们仍然简单地认为,只要日志项被复制到大多数节点上就是 Committed 了,接下来我们会修改日志项 Committed 的条件。
接下来我们开始分析,Raft 是如何能够在复制日志时始终兑现承诺的?
Slide 14
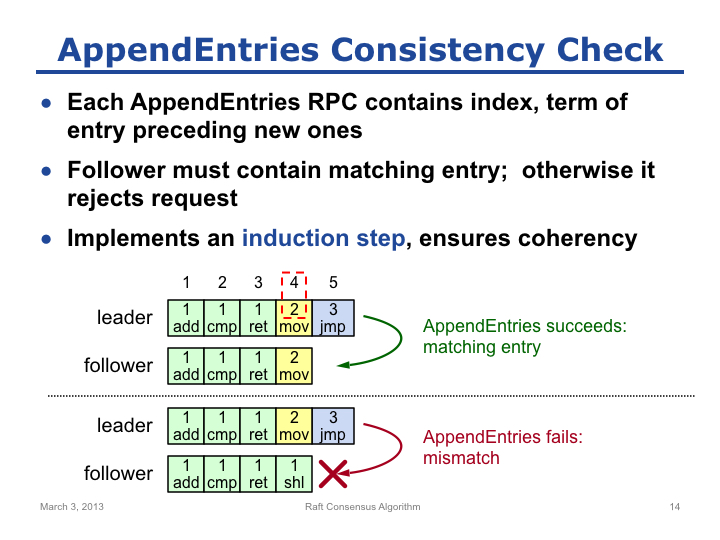
基于 Raft 在复制日志时的承诺,我们可以得出重要的一个结论:Index 和 Term 可以唯一确定一个日志项。也就是说,如果两个日志项有相同的 Index 和 Term,那么这两个日志项的指令一定相同。这是因为如果 Term 相同,说明是同一个 Leader 创建的日志项,而同一个 Leader 在某个 Index 下创建的日志项一定是相同的。这个结论会贯穿我们对 Raft 剩余部分的理解。我们现在关注 Raft 是如何实现承诺的。
Leader 在向 Follower 复制日志时,发送的 AppendEntries 消息内会携带待复制日志项的前一个日志项的 Index 和 Term。当 Follower 收到消息时,并不是无条件的 Append,而是会校验消息中的 Index 值和 Term 值是否等于 Follower 最后一个日志项的 Index 值和 Term 值,只有匹配才会 Append,否则直接拒绝。例如,Slide 14 中 Leader 准备复制 (5,3)日志项,消息中会附带上一个日志项(4,2)至 Follower,Slide 14 描述了两种可能的情况。
基于 Follower 在 Append 日志项时会进行校验,我们尝试证明 Slide 13 中的两个承诺:证明过程实际上就是一个归纳的过程,一开始,所有 Follower 的日志为空时一定是成立,而接下来每次 Append 日志项都会校验前一个日志项是否一致,因此可以保证当前复制成功的日志项之前的所有日志项也都是一致的。
注意:目前我们还不考虑 Leader 发生变更,这意味着 Leader 一定拥有所有已经 Committed 的日志项,那么如果出现 Leader 变更怎么办?我们会继续理解 Raft,实际上 Raft 在 Leader 选举时也有限制条件,并不是任意 Candidate 都能赢得选举。
Slide 15

之前的讨论都是基于 Leader 正常运行时的情况,现在我们看看 Leader 发生变更时 Raft 是怎么处理的。
Slide 15 展示了一种比较混乱的情况,不过我们可以推导 Leader 选举情况。Term 1 各个节点都运行正常,然后发生了 Leader 变更进入 Term 2, S5 成为了 Leader,接着又发生了 Leader 变更,S5 又成为 Leader,在运行一段时间后 S5 崩溃,S4 成为新的 Leader,然后 S4 又崩溃,S3 成为 Leader,然后 S1 成为 Leader,最后 S2 又成为 Leader。期间很可能发生了网络隔离,S1、S2 和 S3 在一个分区,S4 和 S5 在另一个分区。
注意,我们已经强调过,Raft 的目的是要把已经 Committed 的日志项到大部分节点,而那些尚未 Committed 的日志项并不需要复制。如果某个日志项没有 Committed,那么该日志项对应的客户端也不会收到响应,客户端在超时后重试即可。所以,Raft 要做的就是让新选举出来的 Leader 包含所有已经 Committed 的日志项,然后再由 Leader 将 Committed 的日志项复制到其他节点上。因此,如果 Leader 包含所有已经 Committed 的日志项,那么 Leader 就是所谓的 “The Truth”,所以 Leader 只需要把自己的日志项复制到 Follower 就实现了一致。
按照我们目前对 Committed 的定义,Term 1 中的所有日志项以及 Term 5 中 Index 等于 3 的日志项已经是 Committed 的。因此 Raft 要做的就是选举一个拥有所有 Committed 日志项的 Candidate 作为 Leader,然后让 Follower 的日志和 Leader 一致就可以了。整个过程是非常自然:新选举出来的 Leader 并不会先和 Follower 进行日志同步,而是在进行日志复制时进行校验,一旦出现不一致再进行日志的复制。同时,为了和 Leader 达成一致,Follower 势必会舍弃自己原有的尚未 Committed 的日志项。
小结:当 Leader 发生变更,Raft 要求新选举出来的 Leader 必须包含所有已经 Committed 的日志项,Leader 接下来只需要单纯的进行日志复制。 因此,我们接下来需要理解的问题就是:Raft 是如何保证新选举出来的 Leader 一定是拥有所有 Committed 日志项的?
Slide 16

为了保证 Leader 变更时的安全性,Raft 提出了一个 Safe Property:如果一个 Leader 决定某个日志项已经是 Committed 的,那么该日志项会一直出现在未来 Leader 的日志中。 Safe Property 其实是和 Slide 15 提到的概念是一致的,即新选举出来的 Leader 需要包含所有已经 Committed 的日志项。
为了满足安全性需求,Leader 需要满足以下三点。
- Leader 只能 Append 日志项,不能覆盖日志项。需要注意的是,这点仅仅是针对 Leader 的要求,Leader 包含所有已经 Committed 的日志项,同时 Leader 也可能包含某些尚未 Committed 的日志项,Raft 要做的是将已经 Committed 的日志项复制到 Follower,但是如果把 Leader 尚未 Committed 的日志项复制给 Follower,也是没有问题的。而一旦下次出现 Leader 变更,上个 Leader 中尚未 Committed 的日志项也是会被舍弃的。
- 只有在 Leader 中的日志项才能被 Committed。
- 只有已经 Committed 的日志项才能被应用到状态机。
回顾 Slide 15,Raft 要保证新选举出来的 Leader 必须是包含所有已经 Committed 的日志项,接下来我们开始分析 Raft 增加了哪些限制条件来实现这一目标。同时,我们也进一步在日志项 Committed 的定义上增加限制条件。
Slide 17

前文已经说到,新选举出来的 Leader 应该包含所有 Committed 日志项,但是实际上很难界定一个日志项是否是 Committed 的,按照目前对 Committed 的定义,即很难界定一个日志项是否已经被复制到大部分节点。Slide 17 描述了一种场景:存在三个节点,其中日志项 5 已经被复制到大多数节点,即日志项 5 已经是 Committed 的,如果节点 3 突然宕机,需要从剩余 2 个节点中选举 Leader,此时日志项 5 是否已经 Committed 是无法得知的,因为日志项 5 是否 Committed 取决于节点 3,而节点 3 宕机了。
Raft 采取的策略是:选择最有可能包含所有 Committed 日志项的节点作为 Leader。最有可能的含义是指某个节点包含最新且数量最多的日志项。其中最新体现在节点最后一个日志项有最大的 Term,数量最多是在最新的基础上,日志项的 Index 最大。
现在给 Raft Leader 选举增加限制条件:Candidate 给其他节点发送的 RequestVote 消息中会同时携带 Candidate 最后一个日志项的 Term 和 Index,其他节点在收到 RequestVote 消息后,如果发现消息中的 Term 大于自己当前的 Term,或者 Term 相同,但是消息中的 Index 更大,那么可以认为 Candidate 拥有更完整的日志项,因此就会给 Candidate 投票,否则拒绝投票。
Slide 18
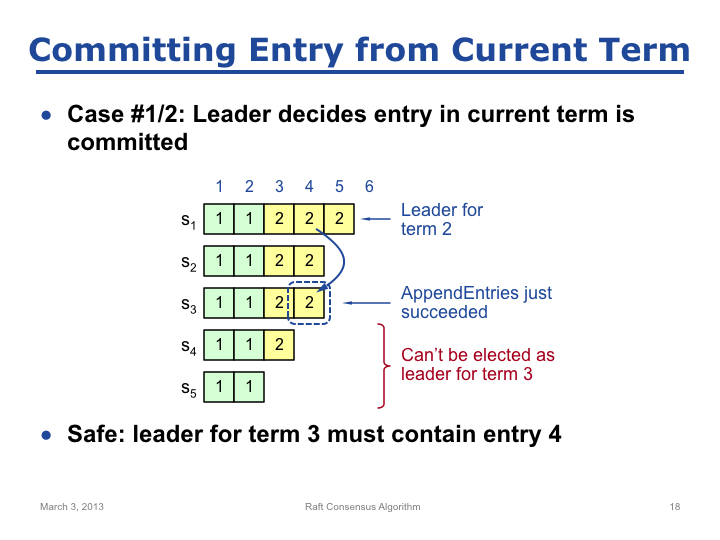
我们以具体的场景进一步理解 Leader 选举。5 个节点,S1 为 Leader,其余均为 Follower。S1 将日志项 4 复制到了 S3,此时日志项 4 已经是 Committed 了。如果现在出现 Leader 变更,S4 最多能够获得来自 S5 的投票,S5 不会获得任何投票,只有 S1、S2 或 S3 可以赢得选举,而 S1、S2 和 S3 都是拥有所有已经 Committed 日志项的节点,所以能够保证安全性。
Slide 19
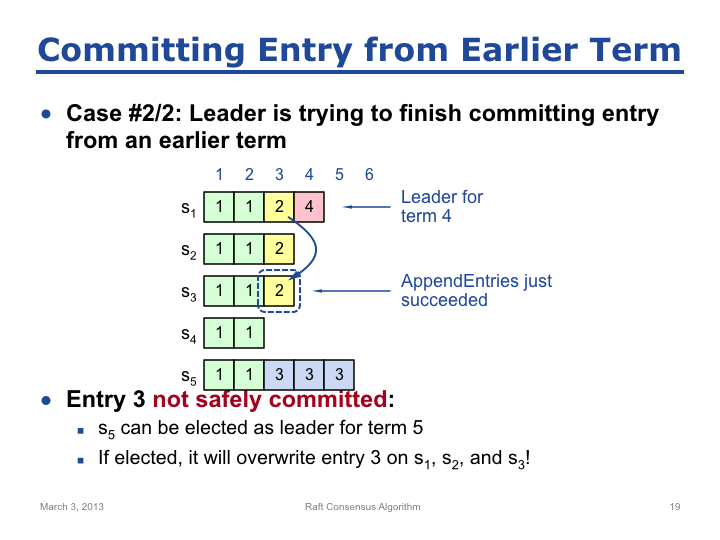
再分析一个场景。5 个节点,S1 当选为 Term 2 的 Leader,复制日志项 2 至 S2后,S1 宕机。在 Term 3,S5 可以获得来自 S3、S4 和自身的投票并当选为 Leader,S5 创建了 3 个日志项后宕机。进入 Term 4,S1 可以获得来自 S2、S3 和 S4 的投票并当选为 Leader,S1 将日志项 3 复制至 S3 后,日志项 3 已经在被复制到了大多数节点,那么此时能否认为日志项 3 是 Committed 的呢?
答案是不能,考虑这种场景:当 S1 把 日志项 3 复制到 S3 后,S1 又宕机了。进入 Term 5,S5 可以获得来自 S2、S3 和 S4 的投票,因为 S5 的 Term 更大,所以 S5 可以当选为 Leader。当 S5 成为 Leader 之后,S3 将会用自己的日志项 3 覆盖 S1、S2 和 S3 的日志项 3,这将导致覆盖已经 Committed 的日志项,显然不能保证安全性。
我们意识到之前关于 Committed 的定义已经不能够保证安全性了,所以我们需要给 Committed 的定义增加限制条件。
Slide 20

为 Committed 的定义增加一条新的限制:只有在当前 Term 内创建的新日志项被复制到大部分节点后,之前 Term 内被复制到大部分节点的日志项才是 Committed 的。可以这么理解,如果当前 Term 内的日志项都已经被复制到了大部分节点,那么该日志项之前的日志项更应该是被复制到了大部分节点。而当前 Term 内的日志项被复制到大部分节点,又可以保证比当前 Term 低的节点不可能在下次选举中成为 Leader。
再次回顾上一个不安全的场景:S1 把在 Term 4 内创建的日志项 4 复制到了大部分节点后,如果 S1 宕机了,S5 是无法获取大部分投票从而无法成为 Leader。因为日志项 4 已经被复制到了大部分节点,所以此时才可以认为日志项 3 已经是 Committed 的。
截止目前,我们梳理完毕 Raft 算法为了保证安全性给 Leader 选举 和 Committed 定义增加的限制条件。
Slide 21

通过增加限制条件,我们现在已经可以保证 Raft 的安全性。当 Leader 选举出来后,有些 Follower 可能缺少日志项,有些 Follower 可能存在无关的未提交日志项。注意,Follower 中如果存在 Leader 不存在的日志项,Follower 并不需要复制给 Leader,因为日志项未提交说明该日志项对应的客户端没有收到响应,客户端可以通过重试解决问题。所以,只需要让 Follower 的日志和 Leader 保持一致即可。
Slide 22
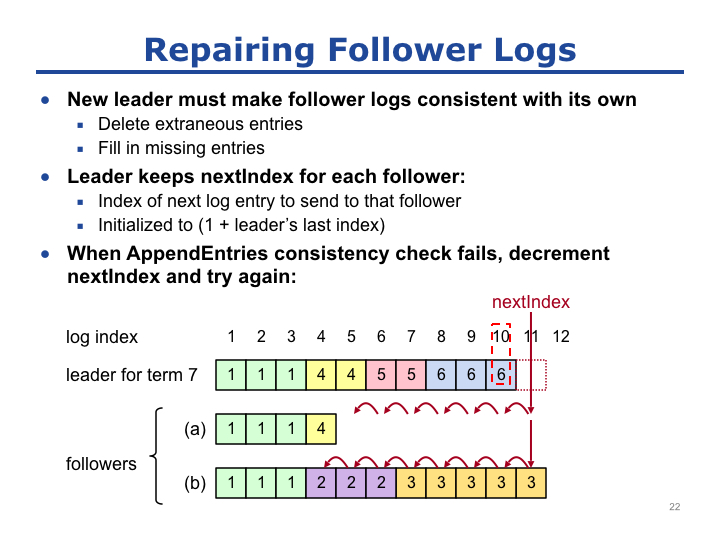
我们已经知道,为了和 Leader 的日志一致,Follower 需要删除不相关的日志项和填充缺失的日志项,那么 Raft 是怎么实现的呢?Leader 为每个 Follower 维护了一个 NextIndex 标记,NextIndex 的值初始化为 Leader 最后一个日志项的 Index 加 1。Leader 在向 Follower 发送 AppendEntries 消息时会发现一致性问题,一旦不一致,那么 NextIndex 减 1。
以 Slide 22 图例说明,Leader 为每个 Follower 的 NextIndex 值初始化为 11,然后进行日志复制,Leader 发送 AppendEntries 消息给 Follower,AppendEntries 消息中会携带 Leader 的最后一个日志项的 Index 和 Term,即(10,6)。如果发生冲突,NextIndex 减 1,Leader 会发送携带(9,6)的 AppendEntries 消息,直至 Leader 发送携带(4,4)的 AppendEntries 消息后,才解决冲突。冲突解决后,Leader 就可以将后续所有的日志项发送给 Follower。
注意,因为在节点刚当选 Leader 时很可能首先会发送心跳消息(不包含日志的 AppendEntries 消息)给 Follower,因此我们认为是最后一个日志项的 Index 和 Term。如果是普通的 AppendEntries 消息(包含日志),依旧发送包含(10,6)的 AppendEntries 消息给Follower,如果一致那么消息中的日志就直接复制给 Follower,如果不一致 NextIndex 减 1。
Slide 23
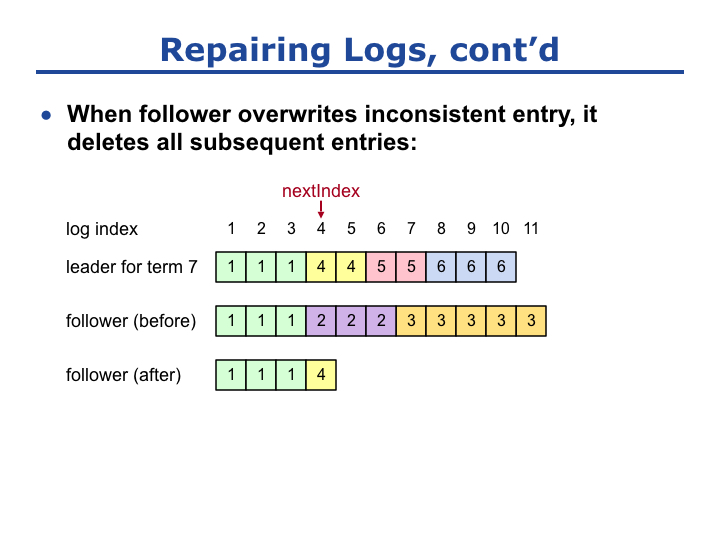
在进行日志复制时,当 Leader 通过调整 NextIndex 找到了冲突日志的起始位置后,就开始复制日志给 Follower。一旦 Follower 的日志项被覆盖,那么该日志项之后的所有日志项都会被舍弃。
以 Slide 23 为例,当 Leader 将 日志项 4 复制给 Follower 后,Follower 日志项 4 之后的所有日志项便是多余的,可以直接舍弃。
小结
Raft 为了保证日志复制时的安全性,为 Leader 选举和日志项的 Committed 增加了限制条件。通过分析各种场景,我们理解了 Raft 增加这些限制条件的原因,以及这些限制条件为什么能够保证安全。