谈谈 RocketMQ 消息存储的设计与实现
作为一款高性能的消息中间件,RocketMQ 基于互联网的生产要求对多 Topic 场景做了诸多针对性优化。根据中间件团队提供的 压测报告,在 Producer 和 Consumer 共存的情况下,相比于 Kafka,RocketMQ 的性能指标(TPS 和 RT)随着 Topic 数量的上升表现稳定。本文从消息存储的角度谈谈 RocketMQ 高性能的原因,重点包括四个方面:消息文件存储的结构设计、消息从 Broker 接收到持久化磁盘的流程、刷盘策略和内存映射优化机制。
消息文件存储结构
与 Kafka 类似,RocketMQ 选择直接操作文件系统来提升存储效率,不同的是,RocketMQ 将消息持久化过程最大化的转化为顺序写。为了进一步理解消息存储结构,本文作者在单机部署了 RocketMQ 并投递一定量的消息。RocketMQ 默认存储路径为 $HOME/store,相关文件目录结构如下。
$ tree ~/store/commitlog ~/store/consumequeue ~/store/index
/Users/chenyang/store/commitlog
├── 00000000000000000000
└── 00000000001073741824
/Users/chenyang/store/consumequeue
└── TopicTest
├── 0
│ ├── 00000000000000000000
│ ├── 00000000000006000000
│ ├── 00000000000012000000
│ ├── 00000000000018000000
│ └── 00000000000024000000
├── 1
│ └── ...
├── 2
│ └── ...
└── 3
└── ...
/Users/chenyang/store/index
└── 20190626213710317
Kafka 以 Topic 作为文件存储的基本单元,即每个 Topic 有其对应的数据文件和索引文件。当存在大量 Topic 时,消息持久化逐渐变成一种随机写磁盘的行为,此时磁盘 IO 成为影响系统吞吐量的主要因素。针对上述问题,RocketMQ 首先将消息的写入转化为顺序写,即所有 Topic 的消息均写入同一个文件(CommitLog)。同时,由于消息仍需要以 Topic 为维度进行消费,因此 RocketMQ 基于 CommitLog 为每个 Topic 异步构建多个逻辑队列(ConsumeQueue)和索引信息(Index):ConsumeQueue 记录了消息在 CommitLog 中的位置信息;给定 Topic 和消息 Key,索引文件(Index)提供消息检索的能力,主要在问题排查和数据统计等场景应用。ConsumeQueue 和 Index 的构建依然遵循顺序写。
RocketMQ 利用 mmap 将文件直接映射到用户态内存地址,由此将对文件的 IO 转化为对内存的 IO。由于使用 mmap 必须明确内存映射的大小,因此 RocketMQ 约定:单个 CommitLog 文件大小等于 1 GB,每条消息及其元信息被顺序追加至文件,文件尾部可能存在空闲区域;单个 ConsumeQueue 文件大小等于 6000000 B,存储 30 W 条记录,每条记录固定 20 B;单个 Index 文件大小等于 420000040 B,包含索引头(IndexHeader)、哈希槽(HashSlot)和消息索引(MessageIndex)。同时,CommitLog 和 ConsumeQueue 以字节偏移量作为文件名,因此第二个 CommitLog 的文件名为 1024 * 1024 * 1024 = 00000000001073741824,而第二个 ConsumeQueue 的文件名为 20 * 30 W = 00000000000006000000。
RocketMQ 以如下图所示存储格式将消息顺序写入 CommitLog。除了记录消息本身的属性(消息长度、消息体、Topic 长度、Topic、消息属性长度和消息属性),CommitLog 同时记录了消息所在消费队列的信息(消费队列 ID 和偏移量)。由于存储条目具备不定长的特性,当 CommitLog 剩余空间无法满足消息时,CommitLog 在尾部追加一个 MAGIC CODE 等于 BLANK_MAGIC_CODE 的存储条目作为结束标记,并将消息存储至下一个 CommitLog 文件。
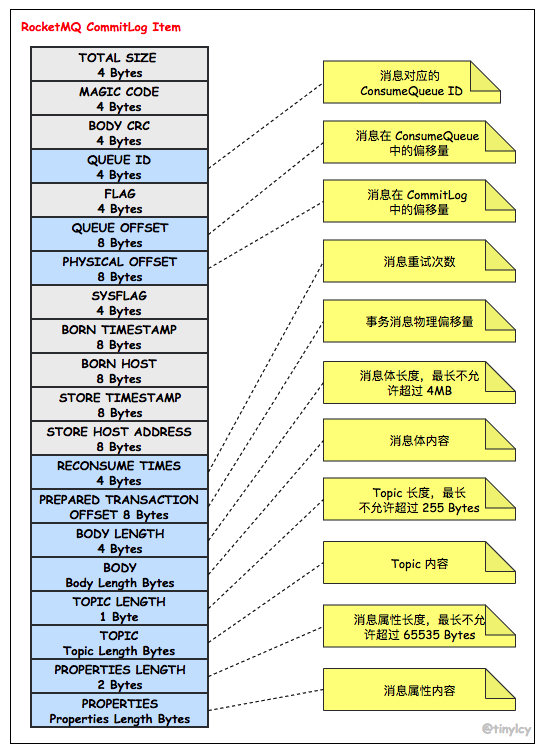
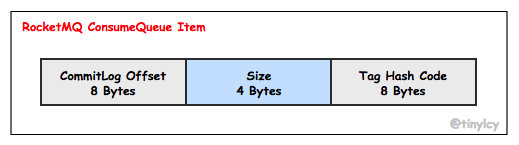
与 CommitLog 不同,ConsumeQueue 的存储条目采用定长存储结构,如下图所示。为了实现定长存储,ConsumeQueue 存储了消息 Tag 的 Hash Code,在进行 Broker 端消息过滤时,通过比较 Consumer 订阅 Tag 的 HashCode 和存储条目中的 Tag Hash Code 是否一致来决定是否消费消息。
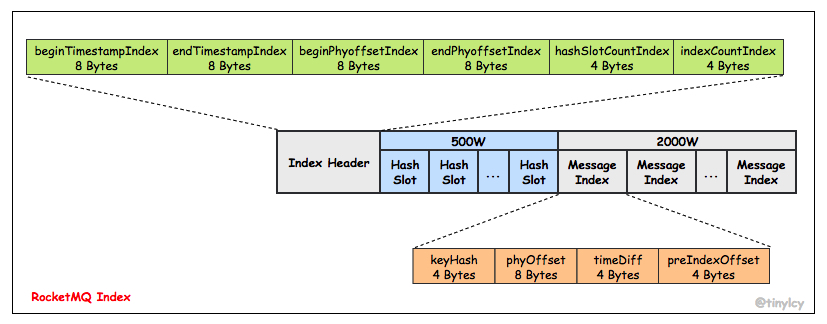
在已有的 CommitLog 和 ConsumeQueue 基础之上,消息中间件的消息发送和消费逻辑已经可以得到满足,RocketMQ 引入 Index 的目的是为消息建立索引方便问题排查:在给定消息 Topic 和 Key 的前提下,快速定位消息。Index 的文件存储结构如下图所示。Index 的整体设计思想类似持久化在磁盘的 HashMap,同样使用链式地址法解决哈希冲突:每个 Hash Slot 关联一个 Message Index 链表,多个 Message Index 通过 preIndexOffset 连接。
本节讨论了 RocketMQ 消息存储相关的核心文件存储结构。无论是 CommitLog,ConsumeQueue 还是 Index,RocketMQ 均使用统一的 MappedFile 来抽象。本文将讨论 RocketMQ 是如何围绕 MappedFile 并结合内存映射来构建 CommitLog(本文对 ConsumeQueue 和 Index 的异步构建不进行讨论)。
消息存储流程
在启动阶段,Broker 将消息处理器注册至核心控制器(BrokerController),Broker 根据请求的 RequestCode 将请求路由至对应的消息处理器。相比于 NameServer 将所有网络通信交由单一的消息处理器处理,Broker 定义了八种消息处理器(AdminBrokerProcessor、ClientManageProcessor、ConsumerManageProcessor、EndTransactionProcessor、ForwardRequestProcessor、PullMessageProcessor、QueryMessageProcessor 和 SendMessageProcessor)。其中,SendMessageProcessor 负责处理消息发送请求,其注册相关的核心代码精简如下。
// org.apache.rocketmq.broker.BrokerStartup#main
public static void main(String[] args) {
start(createBrokerController(args));
}
// org.apache.rocketmq.broker.BrokerStartup#createBrokerController
public static BrokerController createBrokerController(String[] args) {
...
try {
// Configuation initialization.
final BrokerConfig brokerConfig = new BrokerConfig();
final NettyServerConfig nettyServerConfig = new NettyServerConfig();
final NettyClientConfig nettyClientConfig = new NettyClientConfig();
final BrokerController controller = new BrokerController(
brokerConfig,
nettyServerConfig,
nettyClientConfig,
messageStoreConfig);
...
boolean initResult = controller.initialize();
...
return controller;
} catch (Throwable e) {
...
}
return null;
}
// org.apache.rocketmq.broker.BrokerController#initialize
public boolean initialize() throws CloneNotSupportedException {
...
// Create several thread pool service.
this.registerProcessor();
// Create and execute a periodic action.
...
}
// org.apache.rocketmq.broker.BrokerController#registerProcessor
public void registerProcessor() {
SendMessageProcessor sendProcessor = new SendMessageProcessor(this);
sendProcessor.registerSendMessageHook(sendMessageHookList);
sendProcessor.registerConsumeMessageHook(consumeMessageHookList);
this.remotingServer.registerProcessor(RequestCode.SEND_MESSAGE,
sendProcessor,
this.sendMessageExecutor);
...
}
SendMessageProcessor 实现了 NettyRequestProcessor 接口,其对消息的核心处理逻辑实现在 processRequest 方法中,RocketMQ 发送消息包括单个消息发送和批量消息发送,本节以单个消息发送为例进一步说明。不同 Topic 的消息最终均被顺序持久化至共享的 CommitLog,CommitLog 由固定大小的文件队列组成,文件队列被定义为 MappedFileQueue,MappedFileQueue 中每个文件被定义为 MappedFile,每个MappedFile 对应一个具体的文件用于将消息持久化至磁盘。CommitLog、MappedFileQueue 和 MappedFile 之间的依赖关系如下所示。
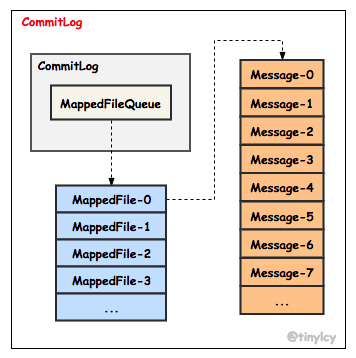
Broker 启动阶段 DefaultMessageStore 被初始化,DefaultMessageStore 是 RocketMQ 消息存储的抽象,提供 CommitLog 的维护、ConsumeQueue & Index 的异步构建(ReputMessageService)、MappedFile 内存映射的分配(AllocateMappedFileService)、HA(HAService) 等保障。DefaultMessageStore 通过 putMessage 方法将消息存储至 CommitLog,核心代码精简如下。
// org.apache.rocketmq.store.DefaultMessageStore#putMessage
public PutMessageResult putMessage(MessageExtBrokerInner msg) {
if (this.shutdown) {
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
if (BrokerRole.SLAVE == this.messageStoreConfig.getBrokerRole()) {
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
if (!this.runningFlags.isWriteable()) {
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
if (msg.getTopic().length() > Byte.MAX_VALUE) {
return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, null);
}
if (msg.getPropertiesString() != null
&& msg.getPropertiesString().length() > Short.MAX_VALUE) {
return new PutMessageResult(PutMessageStatus.PROPERTIES_SIZE_EXCEEDED, null);
}
if (this.isOSPageCacheBusy()) {
return new PutMessageResult(PutMessageStatus.OS_PAGECACHE_BUSY, null);
}
PutMessageResult result = this.commitLog.putMessage(msg);
...
return result;
}
在将消息存储至 CommitLog 之前,需要校验 DefaultMessageStore 状态、当前 Broker 节点角色、DefaultMessageStore 是否允许写入、Topic 和 Properties 是否超长和 PageCache 是否繁忙。校验通过后,消息交由 CommitLog 的 putMessage 方法将消息 append 至 MappedFileQueue 中最后一个 MappedFile。putMessage 方法核心流程(暂不涉及延迟消息)包括:尝试获取最后一个 MappedFile,然后通过对 CommitLog 加锁将 append CommitLog 限定为一种串行操作;如果没有获取到 MappedFile 或者 MappedFile 已满,创建新的 MappedFile;将消息 append 至 MappedFile,如果返回结果为 END_OF_FILE,说明 MappedFile 已经没有足够的剩余空间,创建新的 MappedFile 并将消息重新 append 至新 MappedFile;释放 CommitLog 锁。上述逻辑核心代码精简如下。
// org.apache.rocketmq.store.CommitLog#putMessage
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
...
AppendMessageResult result = null;
...
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
try {
...
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = this.mappedFileQueue.getLastMappedFile(0);
}
...
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
switch (result.getStatus()) {
case PUT_OK:
break;
case END_OF_FILE:
// Create a new file, re-write the message
mappedFile = this.mappedFileQueue.getLastMappedFile(0);
...
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
break;
case ...
}
...
} finally {
putMessageLock.unlock();
}
// 本节暂不讨论 Broker 刷盘策略以及 HA 机制
handleDiskFlush(result, putMessageResult, msg);
handleHA(result, putMessageResult, msg);
return putMessageResult;
}
进一步理解创建 MappedFile 的原理。DefaultMessageStore 初始化期间启动 AllocateMappedFileService 线程。当需要创建 MappedFile 时,首先基于 startOffset 计算 MappedFile 文件名,包括两种场景:如果此时不存在 MappedFile,意味着当前为第一次消息投递或者历史 MappedFile 已经被清理,createOffset 不能简单等于 startOffset % mappedFileSize,以避免 MappedFile 文件名无限制增长;如果此时最后一个 MappedFile 已存在且已满,createOffset 等于最后一个 MappedFile 的 fromOffset + mappedFileSize。消息处理线程基于 createOffset 构建两个连续的 AllocateRequest 并插入 AllocateMappedFileService 线程维护的 requestQueue。AllocateMappedFileService 线程读取 requestQueue 中的 AllocateRequest 异步创建对应的 MappedFile。在创建过程中,消息处理线程通过 CountDownLatch 同步等待 MappedFile 完成创建。思考一个问题,消息处理线程为什么不直接同步创建 MappedFile,而是通过创建一个 AllocateRequest 请求,由 AllocateMappedFileService 线程异步统一处理?构建 AllocateRequest 并插入 requestQueue 的核心代码精简如下。
// org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile
public MappedFile getLastMappedFile(final long startOffset) {
return getLastMappedFile(startOffset, true);
}
// org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile
public MappedFile getLastMappedFile(final long startOffset, boolean needCreate) {
long createOffset = -1;
MappedFile mappedFileLast = getLastMappedFile();
if (mappedFileLast == null) {
createOffset = startOffset - (startOffset % this.mappedFileSize);
}
if (mappedFileLast != null && mappedFileLast.isFull()) {
createOffset = mappedFileLast.getFileFromOffset() + this.mappedFileSize;
}
if (createOffset != -1 && needCreate) {
String nextFilePath = this.storePath + File.separator +
UtilAll.offset2FileName(createOffset);
String nextNextFilePath = this.storePath + File.separator
+ UtilAll.offset2FileName(createOffset + this.mappedFileSize);
MappedFile mappedFile = null;
if (this.allocateMappedFileService != null) {
mappedFile =
this.allocateMappedFileService.putRequestAndReturnMappedFile(nextFilePath,
nextNextFilePath, this.mappedFileSize);
}
...
return mappedFile;
}
return mappedFileLast;
}
// org.apache.rocketmq.store.AllocateMappedFileService#putRequestAndReturnMappedFile
public MappedFile putRequestAndReturnMappedFile(String nextFilePath, String nextNextFilePath, int fileSize) {
int canSubmitRequests = 2;
...
AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;
if (nextPutOK) {
...
boolean offerOK = this.requestQueue.offer(nextReq);
...
canSubmitRequests--;
}
AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);
boolean nextNextPutOK =
this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null;
if (nextNextPutOK) {
if (canSubmitRequests <= 0) {
...
this.requestTable.remove(nextNextFilePath);
} else {
boolean offerOK = this.requestQueue.offer(nextNextReq);
...
}
}
...
AllocateRequest result = this.requestTable.get(nextFilePath);
try {
if (result != null) {
boolean waitOK = result.getCountDownLatch().await(waitTimeOut,
TimeUnit.MILLISECONDS);
if (!waitOK) {
return null;
} else {
this.requestTable.remove(nextFilePath);
return result.getMappedFile();
}
}
} catch (InterruptedException e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
return null;
}
回答上面提出的问题,AllocateMappedFileService 线程循环从 requestQueue 获取 AllocateRequest,AllocateRequest 实现了 Comparable 接口,依据文件名从小到大排序。当需要创建 MappedFile 时,同时构建两个 AllocateRequest,消息处理线程通过 CountDownLatch 将 AllocateMappedFileService 线程异步创建第一个 MappedFile 文件转化为同步操作(RocketMQ 存在大量利用 CountDownLatch 将异步转化为同步的案例),而第二个 MappedFile 文件的仍然创建交由 AllocateMappedFileService 线程异步创建。当消息处理线程需要再次创建 MappedFile 时,此时可以直接获取已创建的 MappedFile。AllocateMappedFileService 线程创建 MappedFile 核心逻辑精简如下。
// org.apache.rocketmq.store.AllocateMappedFileService#run
public void run() {
while (!this.isStopped() && this.mmapOperation()) {}
}
// org.apache.rocketmq.store.AllocateMappedFileService#mmapOperation
private boolean mmapOperation() {
boolean isSuccess = false;
AllocateRequest req = null;
try {
req = this.requestQueue.take();
AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());
...
if (req.getMappedFile() == null) {
MappedFile mappedFile;
if (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
try {
mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();
mappedFile.init(req.getFilePath(), req.getFileSize(),
messageStore.getTransientStorePool());
} catch (RuntimeException e) {
...
mappedFile = new MappedFile(req.getFilePath(), req.getFileSize(),
messageStore.getTransientStorePool());
}
} else {
mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
}
...
req.setMappedFile(mappedFile);
...
}
} catch (InterruptedException e) {
...
} catch (IOException e) {
...
} finally {
...
req.getCountDownLatch().countDown();
}
return true;
}
继续理解 MappedFile 的创建原理。如果 isTransientStorePoolEnable 为 true,MappedFile 会将TransientStorePool 申请的堆外内存(Direct Byte Buffer)空间作为 writeBuffer,写入消息时先将消息写入 writeBuffer,然后将消息提交至 fileChannel 再 flush;否则,直接创建 MappedFile 内存映射文件字节缓冲区mappedByteBuffer,将消息写入 mappedByteBuffer 再 flush。完成消息写入后,更新 wrotePosition(此时还未 flush 至磁盘)。对于 RocketMQ 写入消息时为什么采用两种不同的方式,本文不做过多分析。消息 append 至 MappedFile 核心代码精简如下。
// org.apache.rocketmq.store.MappedFile#appendMessage
public AppendMessageResult appendMessage(final MessageExtBrokerInner msg,
final AppendMessageCallback cb) {
return appendMessagesInner(msg, cb);
}
// org.apache.rocketmq.store.MappedFile#appendMessagesInner
public AppendMessageResult appendMessagesInner(final MessageExt messageExt,
final AppendMessageCallback cb) {
int currentPos = this.wrotePosition.get();
if (currentPos < this.fileSize) {
ByteBuffer byteBuffer = writeBuffer != null ?
writeBuffer.slice() : this.mappedByteBuffer.slice();
byteBuffer.position(currentPos);
AppendMessageResult result = null;
if (messageExt instanceof MessageExtBrokerInner) {
result = cb.doAppend(this.getFileFromOffset(), byteBuffer,
this.fileSize - currentPos,
(MessageExtBrokerInner) messageExt);
} else {
...
}
this.wrotePosition.addAndGet(result.getWroteBytes());
...
return result;
}
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
// org.apache.rocketmq.store.CommitLog.DefaultAppendMessageCallback#doAppend
public AppendMessageResult doAppend(final long fileFromOffset,
final ByteBuffer byteBuffer,
final int maxBlank,
final MessageExtBrokerInner msgInner) {
// PHY OFFSET
long wroteOffset = fileFromOffset + byteBuffer.position();
...
final int msgLen = calMsgLength(bodyLength, topicLength, propertiesLength);
...
// Determines whether there is sufficient free space
if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) {
this.resetByteBuffer(this.msgStoreItemMemory, maxBlank);
this.msgStoreItemMemory.putInt(maxBlank);
this.msgStoreItemMemory.putInt(CommitLog.BLANK_MAGIC_CODE);
byteBuffer.put(this.msgStoreItemMemory.array(), 0, maxBlank);
return new AppendMessageResult(...);
}
// Initialization of storage space
byteBuffer.put(this.msgStoreItemMemory.array(), 0, msgLen);
AppendMessageResult result = new AppendMessageResult(...);
...
return result;
}
如果有足够的剩余空间供消息写入,设置 byteBuffer(writeBuffer/mappedByteBuffer)的 position 等于 wrotePosition,执行 byteBuffer 的 put 方法将字节数组写入即可。如果 MappedFile 没有足够剩余空间(msgLen + END_FILE_MIN_BLANK_LENGTH > maxBlank),向 byteBuffer 写入 BLANK_MAGIC_CODE 后返回 END_OF_FILE,消息处理线程创建新的 MappedFile 并将消息 append 至 byteBuffer,映射关系如下图所示。
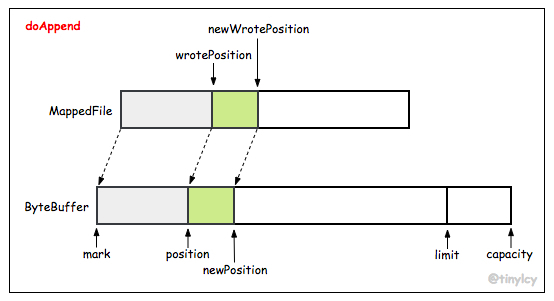
刷盘策略
RocketMQ 刷盘策略分为 commit 和 flush 两阶段,分别由 commitLogService 和 flushCommitLogService 负责,如下图所示:在 commit 阶段,如果 isTransientStorePoolEnable 为 true,数据从 writeBuffer 写入 fileChannel,否则数据仍然驻留在 mappedByteBuffer;在 flush 阶段,将数据从 fileChannel 或者 mappedByteBuffer 持久化至磁盘。
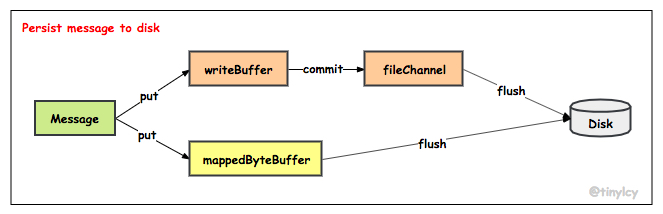
在 CommitLog 构造阶段,commitLogService 被实例化为 CommitRealTimeService,对于同步刷盘,flushCommitLogService 被实例化为 GroupCommitService,对于异步刷盘,flushCommitLogService 被实例化为 FlushRealTimeService。CommitRealTimeService、GroupCommitService 和 FlushRealTimeService 均继承自 ServiceThread 类并实现了 Runnable 接口,在 Broker 启动后创建线程并循环执行相应操作。CommitLog 构造函数及启动代码精简如下。
// org.apache.rocketmq.store.CommitLog#CommitLog
public CommitLog(final DefaultMessageStore defaultMessageStore) {
...
if (FlushDiskType.SYNC_FLUSH ==
defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
this.flushCommitLogService = new GroupCommitService();
} else {
this.flushCommitLogService = new FlushRealTimeService();
}
this.commitLogService = new CommitRealTimeService();
...
}
// org.apache.rocketmq.store.CommitLog#start
public void start() {
this.flushCommitLogService.start();
if (defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
this.commitLogService.start();
}
}
GroupCommitService 线程将 writeBuffer 中的数据 commit 至 fileChannel,执行 commit 有以下两个触发条件。
- writeBuffer 中待 commit 的数据的页数大于等于 commitCommitLogLeastPages,默认为 4 页,每页大小为 4 KB,即当待 commit 的数据超过 16 KB 时,执行 commit 操作。
- 最近 commitCommitLogThoroughInterval 时间间隔内没有执行 commit 操作,主动执行一次 commit 操作,默认为 200 ms。
上述两个触发条件控制了 writeBuffer 中的数据能够在合并后再写入 fileChannel,提升 IO 性能。commit 操作执行完成后,GroupCommitService 唤醒 flushCommitLogService 线程执行 flush 操作。上述流程对应代码精简如下。
// org.apache.rocketmq.store.CommitLog.CommitRealTimeService#run
@Override
public void run() {
while (!this.isStopped()) {
...
int commitDataLeastPages = ...
int commitDataThoroughInterval = ...
long begin = System.currentTimeMillis();
if (begin >= (this.lastCommitTimestamp + commitDataThoroughInterval)) {
this.lastCommitTimestamp = begin;
commitDataLeastPages = 0;
}
try {
boolean result = CommitLog.this.mappedFileQueue.commit(commitDataLeastPages);
long end = System.currentTimeMillis();
if (!result) {
this.lastCommitTimestamp = end; // result = false means some data committed.
//now wake up flush thread.
flushCommitLogService.wakeup();
}
...
} catch (Throwable e) {
...
}
}
...
}
commit 操作本节不再详细讨论,MappedFile 维护的 committedPosition 和 wrotePosition 分别标记了 writeBuffer 中待 commit 数据的起始偏移量和终止偏移量,commit 操作基于此构造 ByteBuffer 并写入 fileChannel。上述流程核心代码如下。
// org.apache.rocketmq.store.MappedFile#commit0
protected void commit0(final int commitLeastPages) {
int writePos = this.wrotePosition.get();
int lastCommittedPosition = this.committedPosition.get();
if (writePos - this.committedPosition.get() > 0) {
try {
ByteBuffer byteBuffer = writeBuffer.slice();
byteBuffer.position(lastCommittedPosition);
byteBuffer.limit(writePos);
this.fileChannel.position(lastCommittedPosition);
this.fileChannel.write(byteBuffer);
this.committedPosition.set(writePos);
} catch (Throwable e) {
...
}
}
}
相比于 Kafka,除了提供异步刷盘的能力,RocketMQ 还提供了同步刷盘的能力。同步刷盘的实现方式类似于 MappedFile 创建,即构造刷盘请求 GroupCommitRequest 写入请求队列,由异步线程 GroupCommitService 消费请求。对于异步刷盘,如果 isTransientStorePoolEnable 为 true,唤醒 CommitRealTimeService 线程将 writeBuffer 中的数据 commit 至 fileChannel,否则唤醒 FlushRealTimeService 线程将 mappedByteBuffer 的数据刷盘。RocketMQ 发起刷盘的核心代码精简如下。
// org.apache.rocketmq.store.CommitLog#handleDiskFlush
public void handleDiskFlush(AppendMessageResult result,
PutMessageResult putMessageResult, MessageExt messageExt) {
// Synchronization flush
if (FlushDiskType.SYNC_FLUSH ==
this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {
GroupCommitRequest request =
new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
service.putRequest(request);
boolean flushOK = request.waitForFlush(...);
if (!flushOK) {
...
}
} else {
service.wakeup();
}
}
// Asynchronous flush
else {
if (!isTransientStorePoolEnable()) {
flushCommitLogService.wakeup();
} else {
commitLogService.wakeup();
}
}
}
为了避免刷盘请求 GroupCommitRequest 的锁竞争,GroupCommitService 线程维护了 GroupCommitRequest 读队列 requestsRead 和写队列 requestsWrite,GroupCommitRequest 的提交和消费互不阻塞。当 GroupCommitService 线程消费完 requestsRead 队列后,清空 requestsRead,交换 requestsRead 和 requestsWrite。上述逻辑核心代码精简如下。
class GroupCommitService extends FlushCommitLogService {
private volatile List<GroupCommitRequest> requestsWrite =
new ArrayList<GroupCommitRequest>();
private volatile List<GroupCommitRequest> requestsRead =
new ArrayList<GroupCommitRequest>();
public synchronized void putRequest(final GroupCommitRequest request) {
synchronized (this.requestsWrite) {
this.requestsWrite.add(request);
}
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
}
private void swapRequests() {
List<GroupCommitRequest> tmp = this.requestsWrite;
this.requestsWrite = this.requestsRead;
this.requestsRead = tmp;
}
private void doCommit() {
synchronized (this.requestsRead) {
if (!this.requestsRead.isEmpty()) {
for (GroupCommitRequest req : this.requestsRead) {
// Invoke force() to flush fileChannel/mappedByteBuffer to disk.
}
...
this.requestsRead.clear();
} else {
...
}
}
}
public void run() {
while (!this.isStopped()) {
try {
this.waitForRunning(10);
this.doCommit();
} catch (Exception e) {
...
}
}
...
synchronized (this) {
this.swapRequests();
}
this.doCommit();
}
...
}
无论是否开启 isTransientStorePoolEnable,异步刷盘交由 FlushRealTimeService 线程处理。在 handleDiskFlush 方法中,如果 isTransientStorePoolEnable 为 true,仅唤醒了 CommitRealTimeService 线程,但是实际上 CommitRealTimeService 线程在 commit 之后也会唤醒 FlushRealTimeService 线程。FlushRealTimeService 线程维护了 lastFlushTimestamp 以标记上次 flush 磁盘的时间点。 FlushRealTimeService 线程 flush 磁盘的触发条件与 GroupCommitService 线程 commit 数据的触发条件类似: fileChannel 或者 mappedByteBuffer 中待 flush 的数据页大小大于等于 flushPhysicQueueLeastPages 页,默认为 4 页;距上次 flush 磁盘时间间隔超过 flushPhysicQueueThoroughInterval,默认为 10 s。最终 FlushRealTimeService 线程调用 fileChannel 和 mappedByteBuffer 的 force 方法将数据刷盘。
内存映射优化
RocketMQ 利用 mmap 将内核空间的一段内存区域映射至用户空间,映射关系一旦建立,应用程序对这段内存区域的修改可以直接反映到内核空间,反之亦然。相比如 read/write 系统调用,mmap 减少了内核空间和用户空间之间的数据拷贝,在存在大量数据传输的场景下可以有效提升 IO 效率。但是,通过 mmap 建立内存映射仅是将文件磁盘地址和虚拟地址通过映射对应起来,此时物理内存并没有填充磁盘文件内容。当实际发生文件读写时,产生产生缺页中断并陷入内核,然后才会将磁盘文件内容读取至物理内存。针对上述场景,RocketMQ 设计了 MappedFile 预热机制。
回顾 MappedFile 的创建流程,AllocateMappedFileService 线程轮询 AllocateRequest 请求队列并创建MappedFile,此时文件系统中已经存在对应的固定大小的文件。当 RocketMQ 开启 MappedFile 内存预热(warmMapedFileEnable),且 MappedFile 文件映射空间大小大于等于 mapedFileSizeCommitLog(1 GB) 时,调用 warmMappedFile 方法对 MappedFile 进行预热。上述逻辑核心代码精简如下。
// org.apache.rocketmq.store.AllocateMappedFileService#mmapOperation
private boolean mmapOperation() {
boolean isSuccess = false;
AllocateRequest req = null;
try {
req = this.requestQueue.take();
...
if (req.getMappedFile() == null) {
MappedFile mappedFile;
if (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();
mappedFile.init(req.getFilePath(), req.getFileSize(),
messageStore.getTransientStorePool());
} else {
mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
}
...
// pre write mappedFile
if (mappedFile.getFileSize() >= getMapedFileSizeCommitLog()
&& isWarmMapedFileEnable()) {
mappedFile.warmMappedFile(getFlushDiskType(),
getFlushLeastPagesWhenWarmMapedFile());
}
...
}
} catch (InterruptedException e) {
...
} catch (IOException e) {
...
} finally {
...
}
return true;
}
warmMappedFile 每间隔 OS_PAGE_SIZE 向 mappedByteBuffer 写入一个 0,此时对应页恰好产生一个缺页中断,操作系统为对应页分配物理内存。同时,如果刷盘策略为同步刷盘,需要对每页进行刷盘。最后,通过 JNA 调用 mlock 方法锁定 mappedByteBuffer 对应的物理内存,阻止操作系统将相关的内存页调度到交换空间(swap space),以此提升后续在访问 MappedFile 时的读写性能。warmMappedFile 核心代码精简如下。
// org.apache.rocketmq.store.MappedFile#warmMappedFile
public void warmMappedFile(FlushDiskType type, int pages) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
int flush = 0;
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
if (type == FlushDiskType.SYNC_FLUSH) {
if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {
flush = i;
mappedByteBuffer.force();
}
}
// prevent gc
if (j % 1000 == 0) {
...
}
}
// force flush when prepare load finished
if (type == FlushDiskType.SYNC_FLUSH) {
mappedByteBuffer.force();
}
this.mlock();
}
// org.apache.rocketmq.store.MappedFile#mlock
public void mlock() {
final long address = ((DirectBuffer) (this.mappedByteBuffer)).address();
Pointer pointer = new Pointer(address);
{
int ret = LibC.INSTANCE.mlock(pointer, new NativeLong(this.fileSize));
}
...
}
总结
为了实现高性能的消息中间件,RocketMQ 做了诸多性能优化。本文结合源码分析了 RocketMQ 消息存储的设计与实现,重点对支持顺序写的消息存储结构、MappedFile 创建、异步线程结合 CountDownLatch 实现任务执行的异步转同步、堆外内存、MappedFile 内存预热 和 JNA 内存锁定展开了讨论。
参考
[1] https://github.com/apache/rocketmq
[2] http://jm.taobao.org/2016/04/07/kafka-vs-rocketmq-topic-amout/
[3] https://rocketmq.apache.org/docs/quick-start/
[4] http://man7.org/linux/man-pages/man2/mmap.2.html
[5] http://man7.org/linux/man-pages/man2/mlock.2.html